聊聊AI和MCP

Table of Contents
1. MCP是什么 #
AI大模型爆发后的今天,体验过大模型的强大后应该很少会有人质疑大模型的能力。但是很多人都注意到了它的致命缺点:它是离线的。 相当于给了你一个很强大的电脑,但是拔掉了网线,它既不能依靠强大的互联网查找资料也不能直接帮你完成工作。 因此Model Context Protocol (MCP)出现了,官方给出的定义是:
MCP is an open protocol that standardizes how applications provide context to LLMs.
简单来说MCP是一套标准,定义了如何给大模型提供现实世界上下文(数据)。
2. MCP如何工作 #
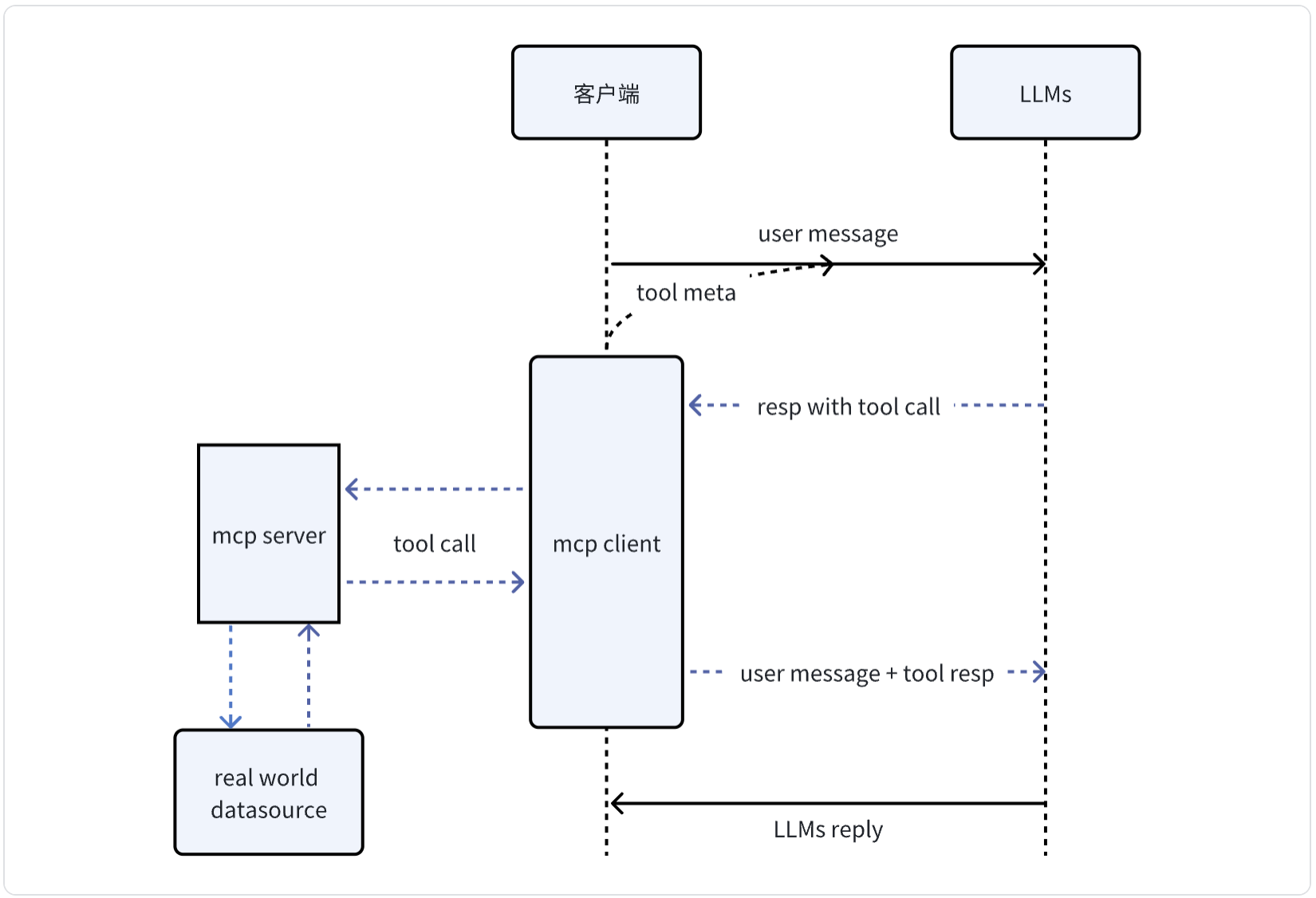
先从全局交互/抽象层面来看,MCP其实是把用户一次对话请求拆分成两次/多次底层对话请求:
- 将用户消息和mcp tool元信息合并发送给大模型
- 大模型根据用户消息和云信息决定是否需要/使用哪个 tool call,并且从用户输入中提取所需参数
- 发起mcp tool调用,将结果和用户消息合并再次发送给大模型
- 得到结果返回给用户
MCP server主要职责是:
- 我能做什么: 通过meta信息告诉大模型自己有几个工具能力,分别能做什么
- 怎么让我做事: 进行特定工具调用时需要哪些参数,该怎么传递参数
- 做事: 按照参数要求与现实世界交互,返回结果
3. 大模型为什么强大 #
可以从信息交互的角度思考,日常工作学习内容很大一部分可以抽象成对信息的:
- 搜寻: 分析需求,搜寻相关信息
- 加工: 对信息加工处理,得出进一步信息,或者再次搜寻补充信息
- 输出: 将加工的信息或者结论按照需要的格式输出
解决现实问题每一步会复杂很多,并且都有各种各样的工具辅助,但本质是不变的。
例如,输出某上市公司经营状况分析报表:
- 使用搜索引擎或者公司内部资料查找相关信息
- 使用excel等工具处理各种报表,输出需要的信息
- 将信息总结整合成结论,按照报表的格式输出
整个过程会用到很多工具,发现工具的本质还是对信息的:输入-加工-输出,因此工具的交互就是传递这三个信息:
- 输入是什么?
- 怎么处理/加工?
- 想要什么样的结果?
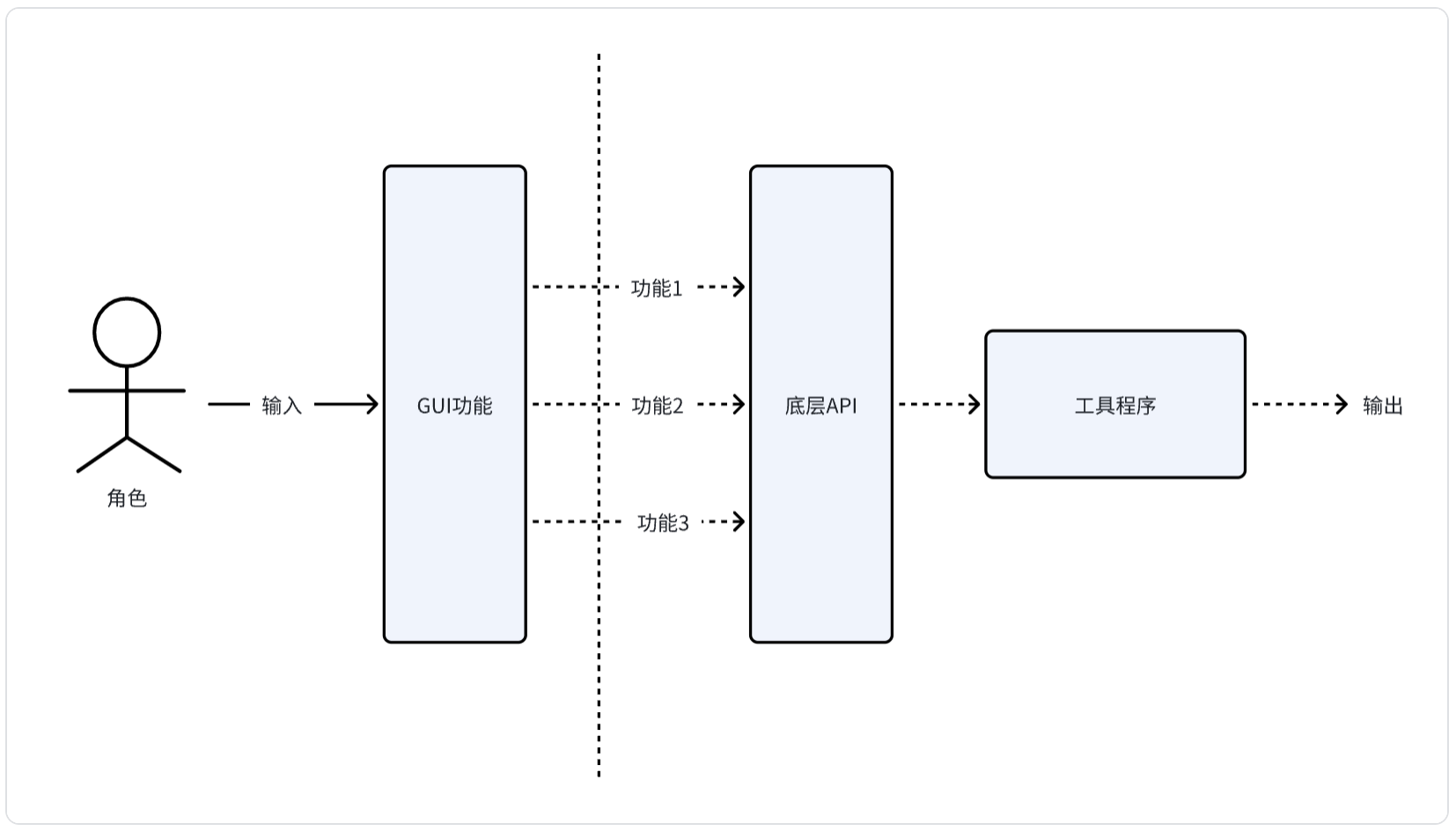
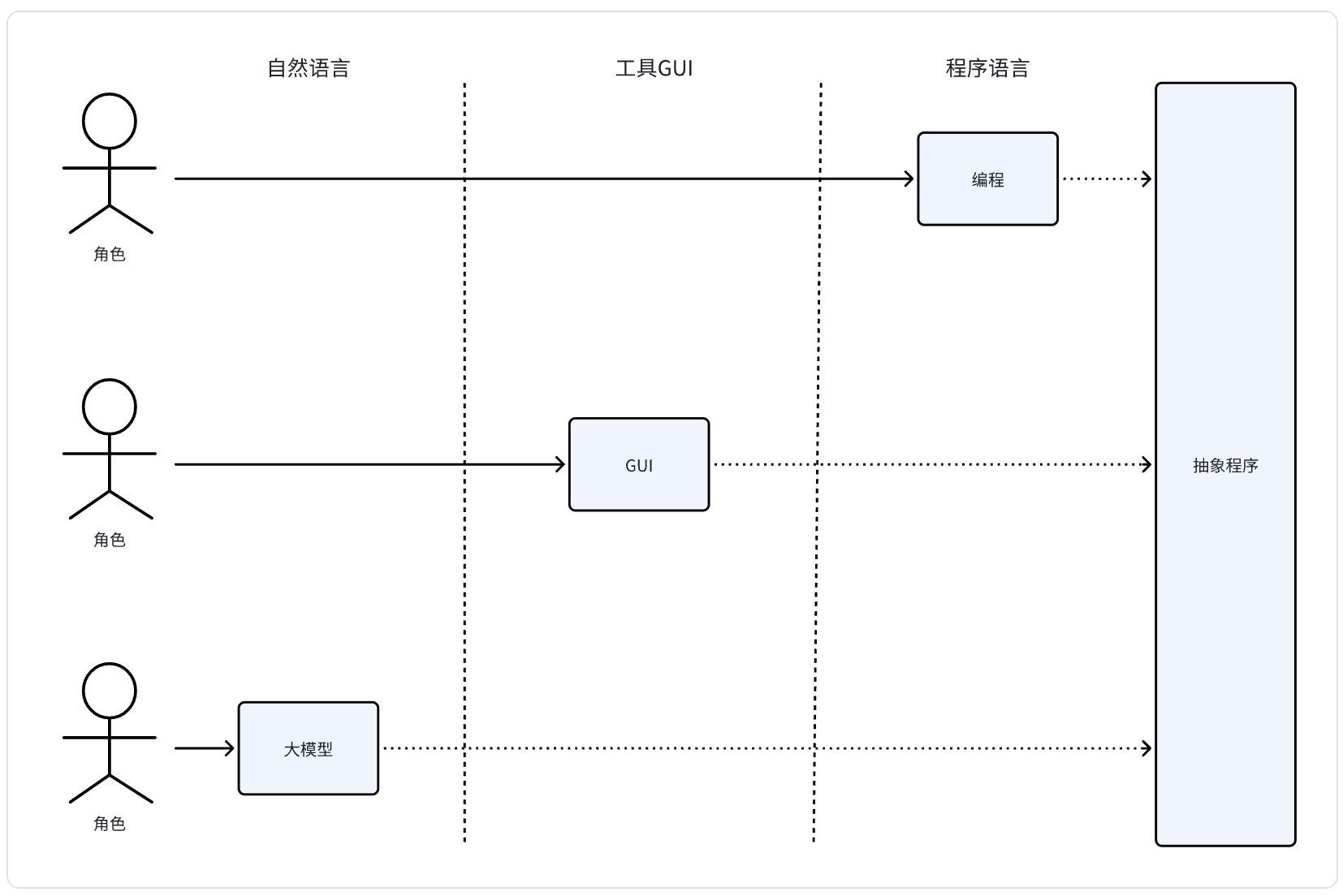
工具软件的本质是:实现多个原子化模块功能,绑定到用户门槛低的GUI操作功能上。
人使用工具的技巧是:按需决策使用哪些工具,并且需要按照什么步骤(拆分成原子化功能)分别使用哪些功能。
之所以要拆分成多个步骤本质还是人向工具/程序的妥协,人只能使用工具已经支持的功能,并且将需求/数据转化成工具手册要求的方式和工具交互。
因此上图需要补充很关键的步骤:
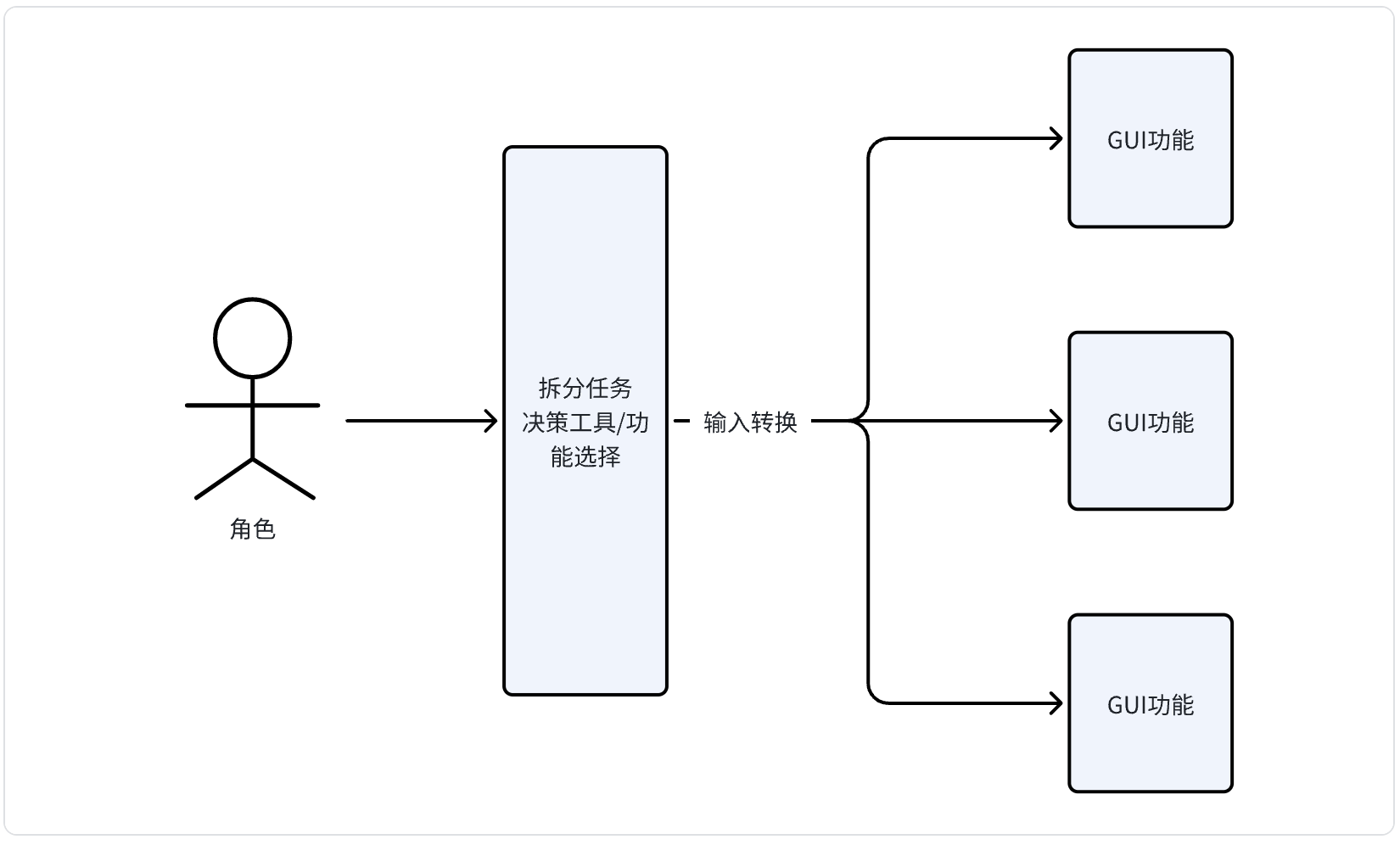
由此也能看出传统工具的缺点是:功能总是有限的。
回到正题,软件界面功能交互解决的都是信息传递问题。更抽象来说,工具功能相当于定义接口,人需要将信息转换成接口需要的格式输入。
进一步,工具交互界面是因为要解决问题不得不定义获取用户输入的方式,并不是解决问题的本质,也就是说解决问题并不是非得按照工具功能拆分成几步处理,仅仅是你只能这么和工具交互。
那么大模型强大的根本原因就是:使用自然语言解决人和工具信息传递。
传统交互形式本质还是人适应机器,而大模型是机器来适配人(理想情况下,实际还是卑微地各种调整prompt)。
4. MCP为什么强大 #
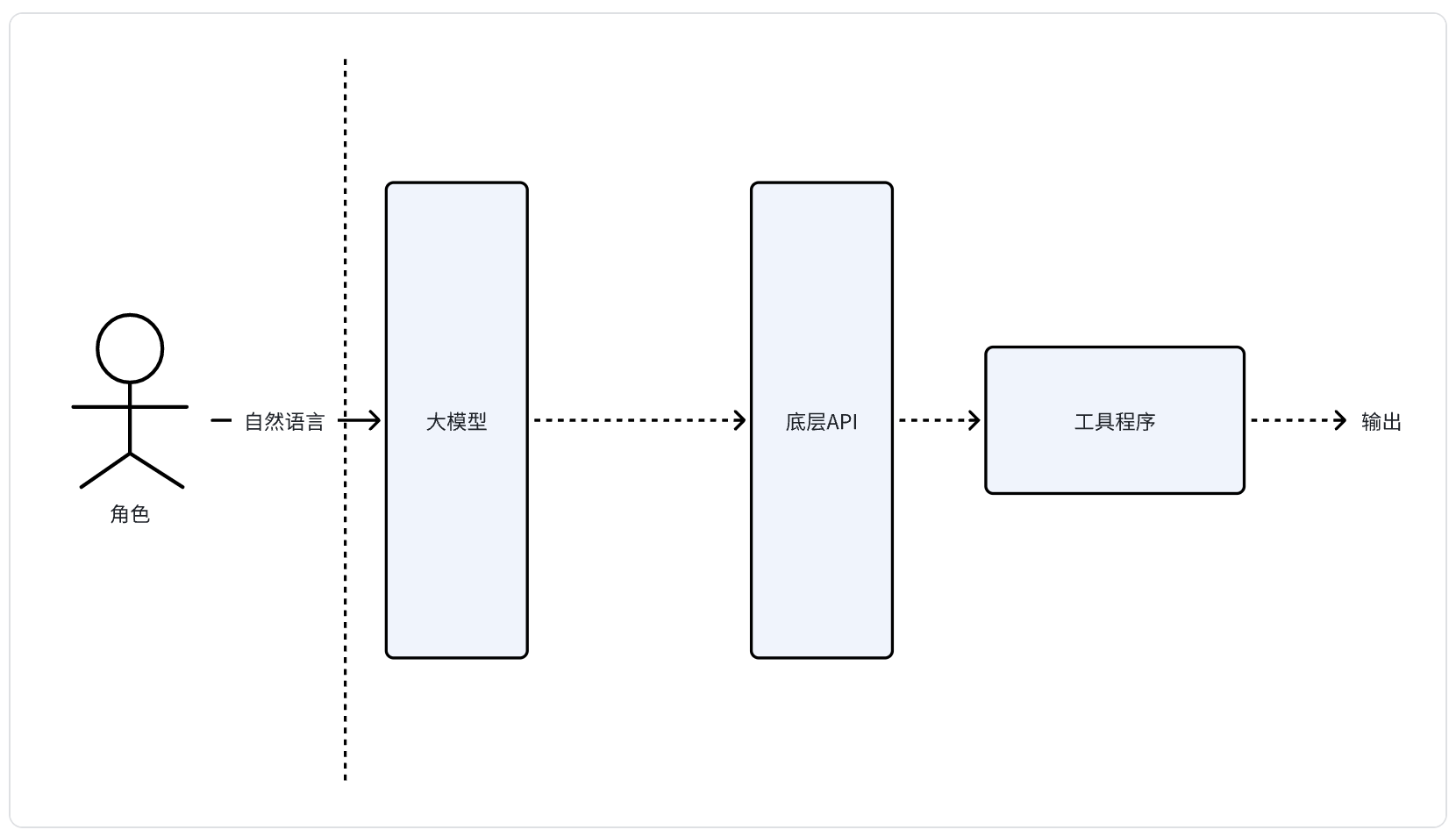
上面说了:MCP可以为离线的大模型提供和现实世界交互的能力。最强大的点是:这个交互是可以复用当前系统传统的交互方式! 类似于做系统演进,对于未升级的旧模块先做一层bridge,让新系统可以使用旧系统的能力。
更简单的描述是:通过大模型让用户可以使用自然语言调用程序API。
我总结了MCP应用三个场景:
- 自主信息获取(提效): 传统模式需要用户完成这一步再输入给大模型
- 行动执行(从0到1): 从仅提供“建议”到直接执行方案
- 能力强化(从0到1): 某些垂直领域采用更为成熟的严谨程序,提升精准度
5. MCP编写使用注意事项 #
5.1 mcp服务需要严进宽出,meta信息就是prompt #
输入层: 大模型 -> mcp server -> 底层API,因为实际应用的API参数总是严谨的,这是编程高门槛的原因之一。
输出层: 底层API -> mcp server -> 大模型,只要是输入给大模型的都是可以模糊的,这是大模型强大的原因之一。
因此mcp server的meta信息尤为重要,它会作为prompt的一部分发送给大模型:
- Description 信息: 能力描述,作为输入让大模型决定是否/使用哪个工具
- Input schema信息:工具输入参数信息,描述使用工具需要的参数/类型,让大模型完成用户输入->API输入的转换,或者提示用户补充信息
大模型总会有幻觉或者不准确的场景,对于普通的交互还算能够接受,因为返回给人的信息部分正确也是有意义的,然而API参数是需要严谨的,它不会惯着任何人,所以提升meta信息的质量就是在优化prompt。
对于只读query的mcp工具来说参数错误不会造成什么副作用,但是对于mutation类型的工具,参数错误可能会造成实际的事故或者风险。
5.2 输出预处理 #
虽然mcp输出是给大模型使用的,大模型的输入信息是可以宽泛的,但是上下文的长度总是有限的和有成本的。因此对于范式化的场景可以通过增加输入参数的方式通过程序对输出信息进行简化。既可以减少返回,又可以聚焦信息。
如果你真实使用过github-mcp,就会感觉其实没那么好用,mcp服务并不是简单包装下restful API就结束了的。
5.3 按需开启工具 #
相信你也注意到了,你的一切操作都是对大模型的输入,包括开启多个mcp工具,从mcp交互流程图可以看到所有mcp工具的meta信息都会被追加到用户消息中发送给大模型,因此工具是否开启本身就是带有信息量的。
在使用大模型时,你的输入信息权重又非常高,因此开启多个mcp工具时,会发现大模型总是想“炫技”想方设法往某个工具上面靠,就是这个原因。
所以mcp工具不能像大模型那样大而宽,而是需要更加垂直和深入。
6. 一些展望 #
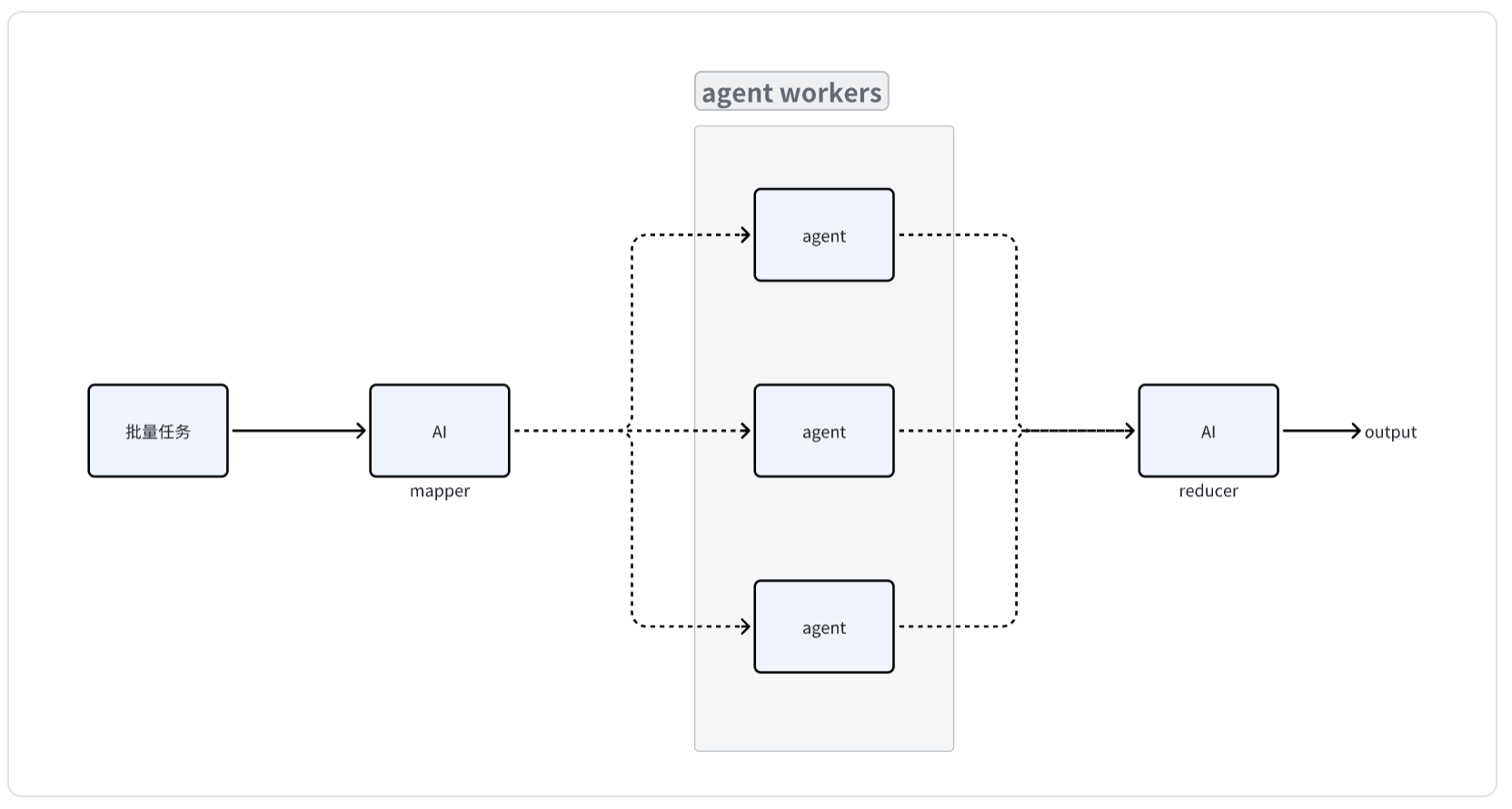
- Prompt + mcp tool = agent
更加强大的垂直领域agent,上面也说了mcp是对大模型的增强,之前基于prompt模板的垂直领域agent可以进化到下个阶段:打包调优后的prompt和mcp tool来解决特定场景问题。
- 复杂任务处理编排能力
拆分复杂任务到多个简单任务解决再合并的方法论体现在在生活的方方面面,传统的工具或者代码一般都会提供任务拆分编排能力,最基本的就是批量重复任务处理,AI工具也得跟上。